|
I am a fourth year Ph.D student in
i-VisionGroup in
the Department of Automation at Tsinghua University, advised by Prof. Jianjiang Feng
and Prof.
Jie Zhou
.
I have a broad interest in computer vision, pattern recognition and human computer interaction. At present, my research mainly focus on MLLMs, computer vision and Image Retrieval. |

|
|
|
|
* indicates equal contribution |
|
|
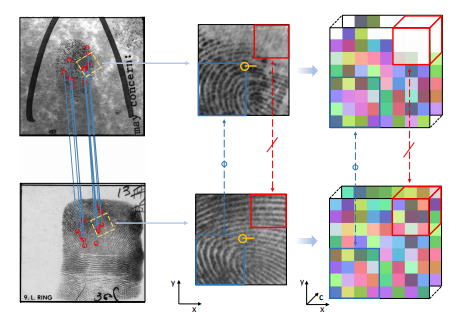
ZhiyuPan , Xiongjun Guan , Jianjiang Feng , Jie Zhou [Paper] [Code] we propose DMD, a minutiae-anchored local dense representation which captures both fine-grained ridge textures and discriminative minutiae features in a spatially structured manner. Specifically, descriptors are extracted from local patches centered and oriented on each detected minutia, forming a three-dimensional tensor, where two dimensions represent spatial locations on the fingerprint plane and the third encodes semantic features. |
|
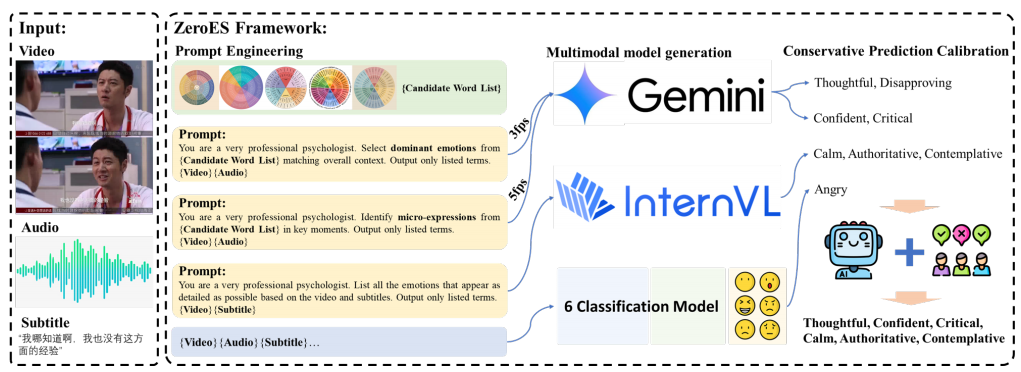
2nd place in International Conference on Multimedia (MM) competition , 2025 Jun Xie *, Xiaohui Fan *, Zhenghao Zhang, Feng Chen, Hongzhu Yi, Yinjian Zhu, Xiongjun Guan, Xinming Wang, Yue Bi, Tao Zhang, Zhepeng Wang [Paper] [Challenge] Emotion recognition has long grappled with the inherent subjectivity and open-ended nature of human affect, where predefined taxonomies falter against the vast, evolving spectrum of emotional expression. We present ZeroES, a Zero-Shot Ensemble framework that redefines open-vocabulary video emotion recognition by leveraging the raw capacity of large-scale vision-language models (VLMs) without task-specific optimization. |
|
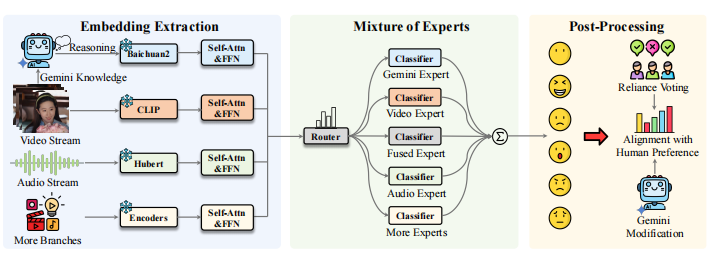
Jun Xie *, Yingjian Zhu *, Feng Chen, Zhenghao Zhang, Xiaohui Fan, Hongzhu Yi, Xinming Wang, Chen Yu, Yue Bi, Zhaoran Zhao, Xiongjun Guan (corresponding author), Zhepeng Wang 2nd place in International Conference on Multimedia (MM) competition , 2025 [Paper] [Code] [Challenge] We propose a robust Mixture of Experts (MoE) emotion recognition framework that integrates diverse modalities, including Vision-Language Models and Action Unit information. Using consensus-based pseudo-labeling and a two-stage training process, we enhance label quality and reduce bias through multi-expert voting and rule-based re-ranking for human-aligned predictions. |
|
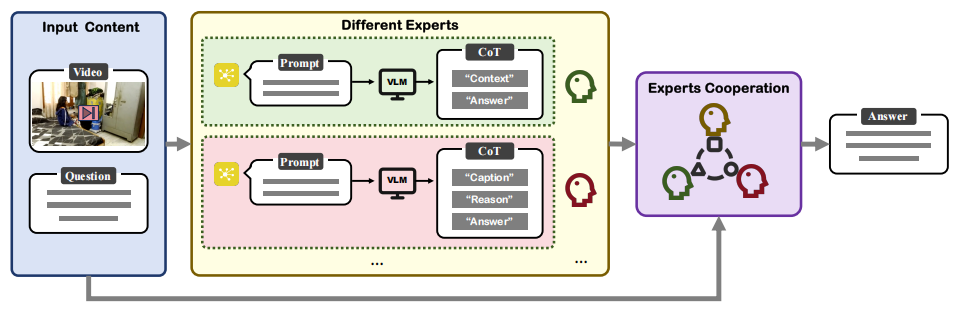
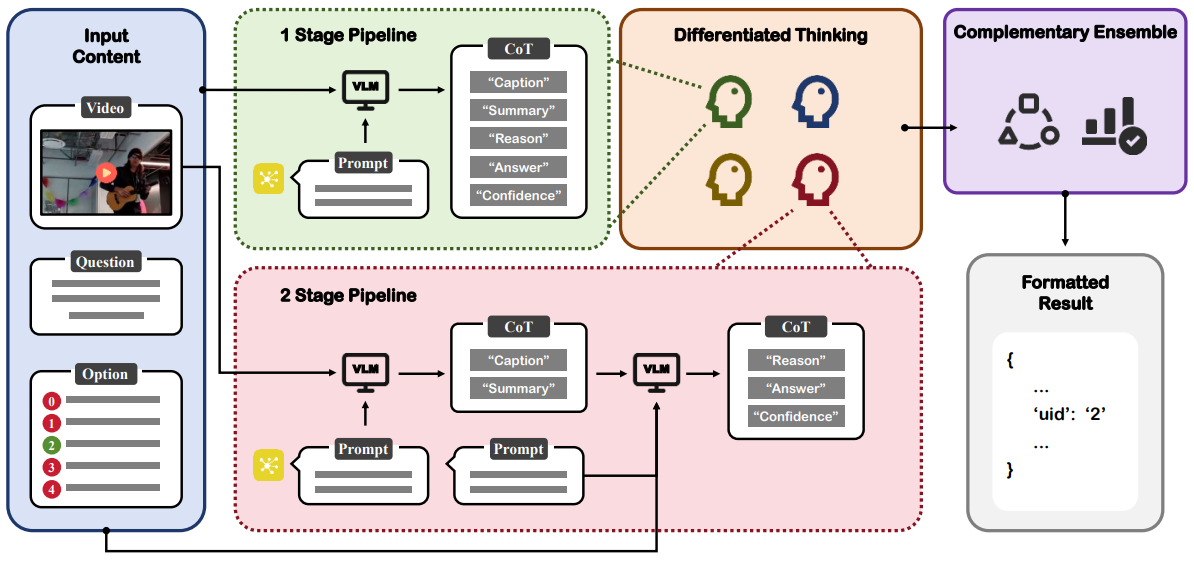
Jun Xie *, Zhaoran Zhao *, Xiongjun Guan , Yingjian Zhu, Hongzhu Yi, Xinming Wang, Feng Chen, Zhepeng Wang 2nd place in Computer Vision and Pattern Recognition (CVPR) competition , 2025 [Paper] [Challenge] We propose a novel framework for open-ended video question answering that enhances reasoning depth and robustness in complex real-world scenarios, as benchmarked on the CVRR-ES dataset. |
|
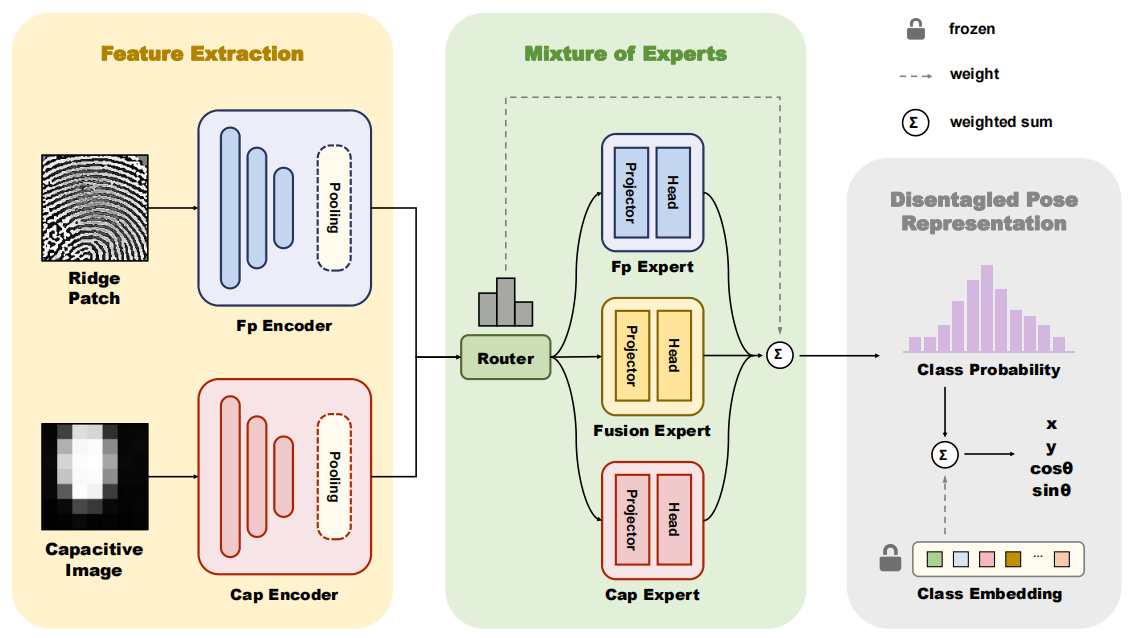
Xiongjun Guan , ZhiyuPan , Jianjiang Feng , Jie Zhou [Paper] [Code] We introduce a partial fingerprint pose estimation framework that leverages the collaborative potential of Dual-modal guidance from Ridge patches And Capacitive images to Optimize the feature extraction, fusion and representation. Several simple but effective strategies and mechanisms are introduced, including knowledge transfer, MoE, and decoupled probability distribution, to enhance the network's capacity for information mining and interaction. |
|
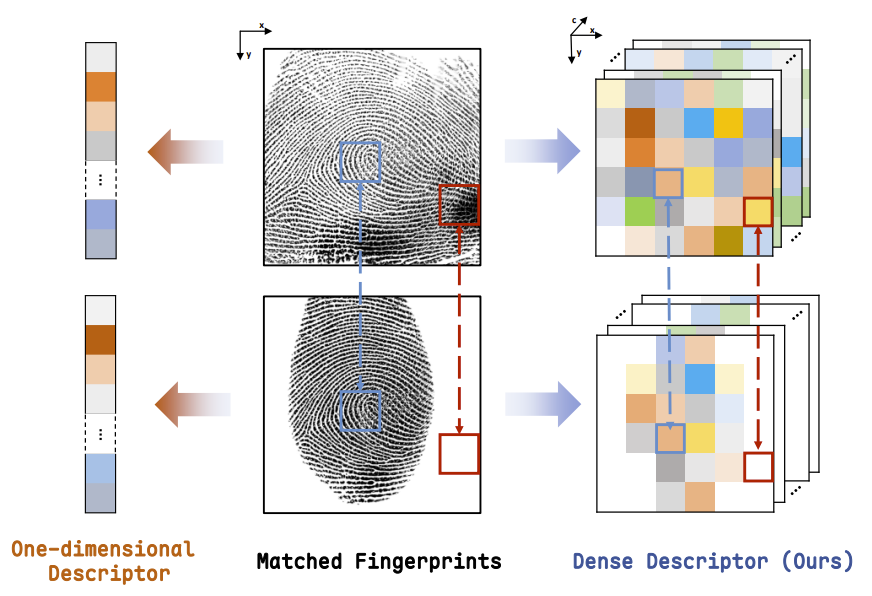
ZhiyuPan , Xiongjun Guan , Jianjiang Feng , Jie Zhou [Paper] [Code] In this work, we propose a fixed-length dense descriptor of fingerprints, and introduce FLARE—a fingerprint matching framework that integrates the Fixed-Length dense descriptor with pose-based Alignment and Robust Enhancement. This fixed-length representation employs a three-dimensional dense descriptor to effectively capture spatial relationships among fingerprint ridge structures, enabling robust and locally discriminative representations. |
|
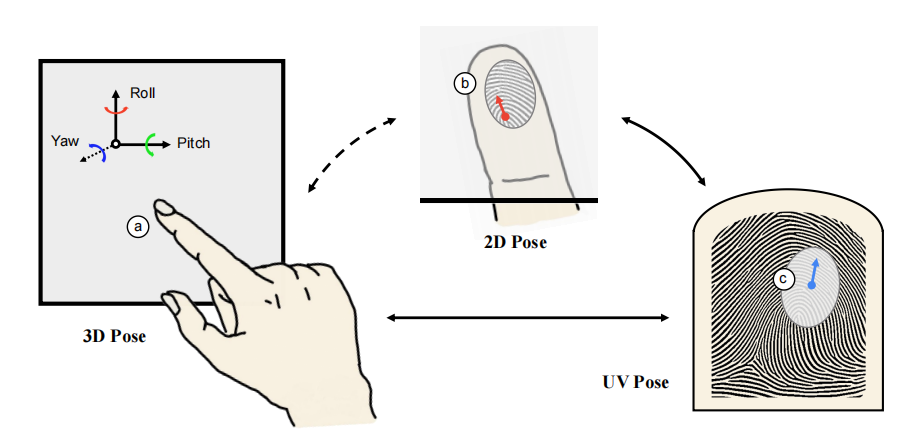
Xiongjun Guan , ZhiyuPan , Jianjiang Feng , Jie Zhou (under review) In this paper, we estimate the 2D finger pose using a multimodal network and map it to a standardized UV space, followed by nearly lossless mapping to 3D space using simple polynomial functions. We further highlight the applicability and appeal of finger pose in enhancing interactive experiences, and develop several prototypes to demonstrate the potential for interaction. |
|

|
Haoxiang Pei, ZhiyuPan , Xiongjun Guan , Jianjiang Feng , Jie Zhou International Joint Conference on Biometrics (IJCB), 2025 Oral Presentation [Paper] [Code] We demonstrate that 3D pose information of contactless fingerprints can be utilized to enhance the robustness and performance of existing recognition systems by guiding the acquisition process and constraining finger poses. |
|
Jun Xie *, Xiongjun Guan * (first student author),Yingjian Zhu, Zhaoran Zhao, Xinming Wang, Hongzhu Yi, Feng Chen, Zhepeng Wang 2nd place in Computer Vision and Pattern Recognition (CVPR) competition , 2025 [Paper] [Challenge] [Code] We present the runner-up solution for the Ego4D EgoSchema Challenge at CVPR 2025 (Confirmed on May 20, 2025). Inspired by the success of large models, we evaluate and leverage leading accessible multimodal large models and adapt them to video understanding tasks via few-shot learning and model ensemble strategies. |
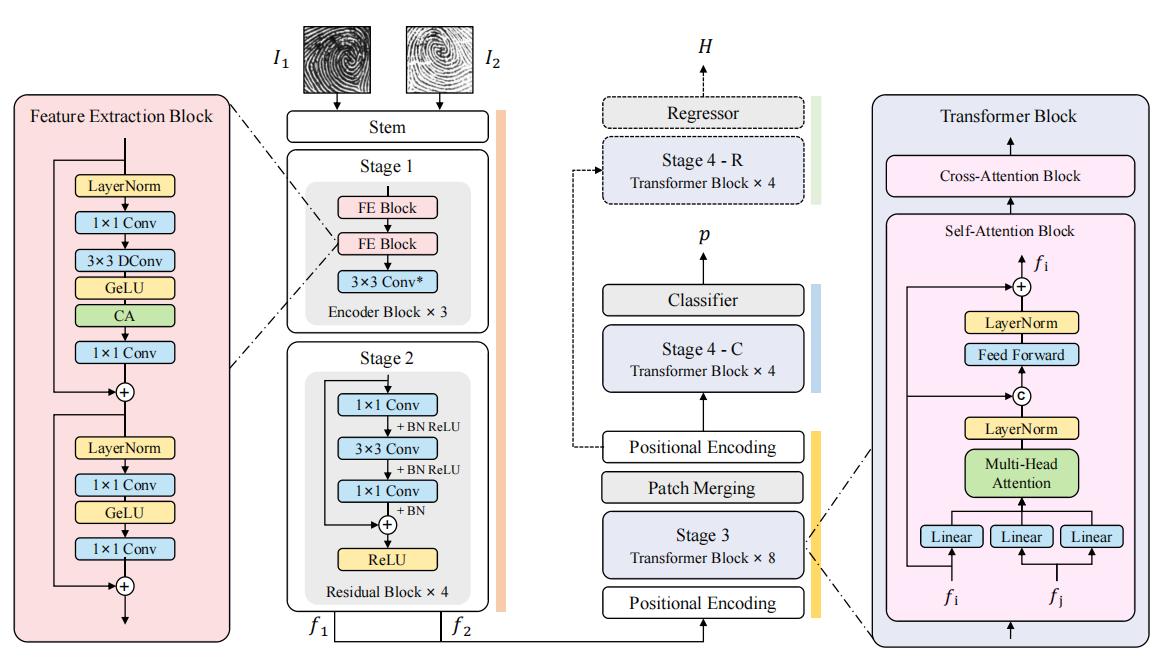
|
Xiongjun Guan , ZhiyuPan , Jianjiang Feng , Jie Zhou IEEE Transactions on Information Forensics and Security (T-IFS), 2025 [Paper] [Code] A novel framework for joint partial fingerprint identity verification and pose alignment of partial fingerprint pairs is proposed, which utilizes a multi-task CNN-Transformer hybrid network and a pre-training task on enhancement. |
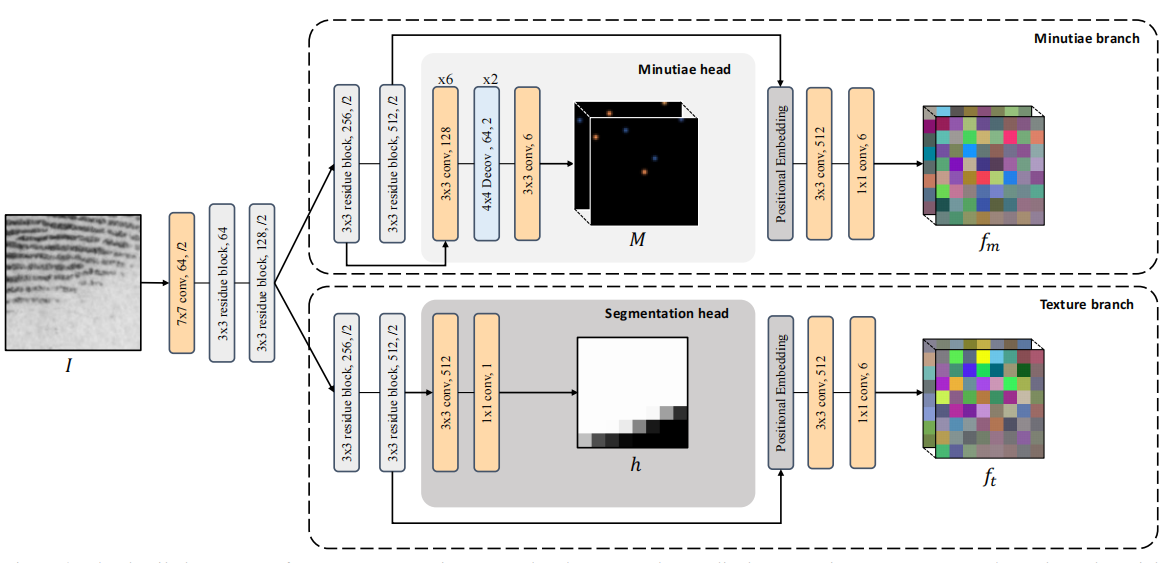
|
ZhiyuPan , Yongjie Duan , Xiongjun Guan , Jianjiang Feng , Jie Zhou International Joint Conference on Biometrics (IJCB), 2024 [Paper] [Code] Latent fingerprint matching is a daunting task, primarily due to the poor quality of latent fingerprints. In this study, we propose a deep-learning based dense minutia descriptor (DMD) for latent fingerprint matching. |
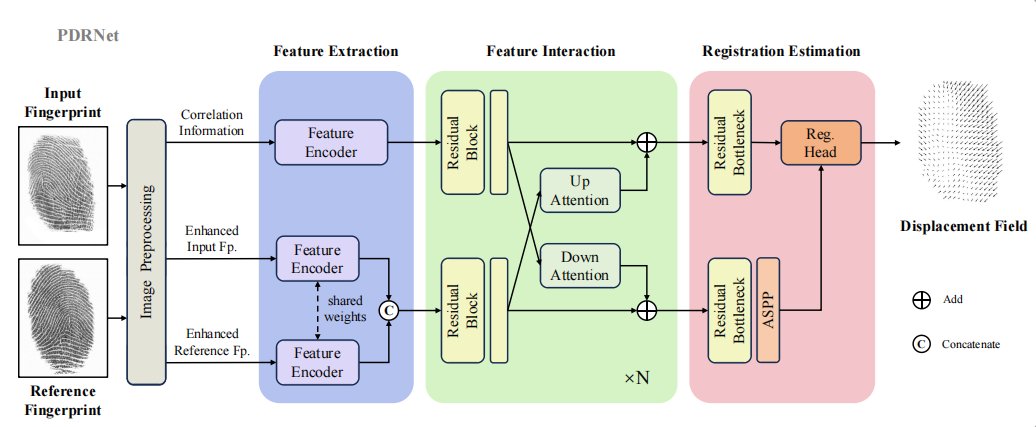
|
Xiongjun Guan , Jianjiang Feng , Jie Zhou IEEE Transactions on Information Forensics and Security (T-IFS), 2024 [Paper] [Code] We propose a Phase-aggregated Dual-branch Registration Network to combine the strengths of traditional fingerprint dense registration methods and deep learning. |
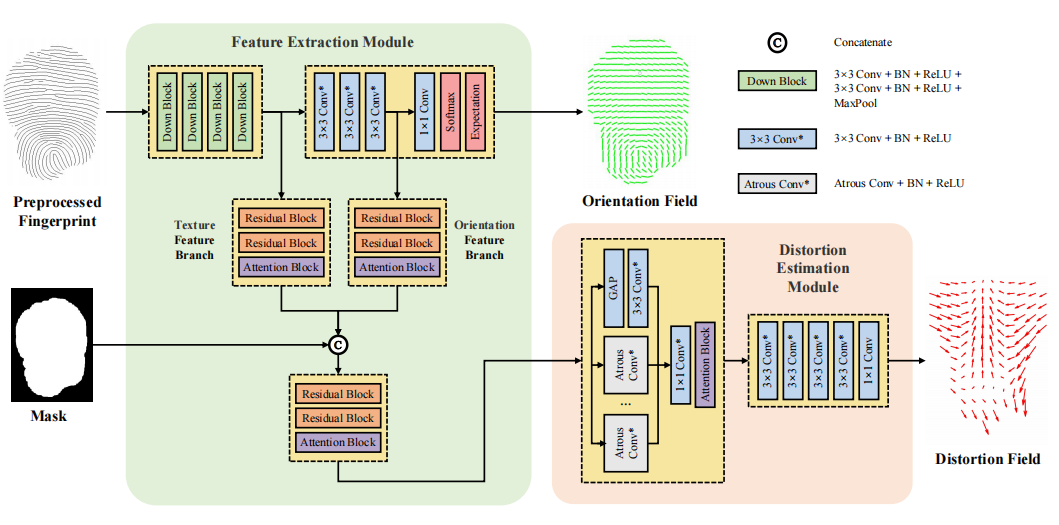
|
Xiongjun Guan , Yongjie Duan , Jianjiang Feng , Jie Zhou IEEE Transactions on Information Forensics and Security (T-IFS), 2023 [Paper] [Code] We proposed an end-to-end network to directly estimate a dense distortion field instead of its low dimensional representation, from a single fingerprint. |
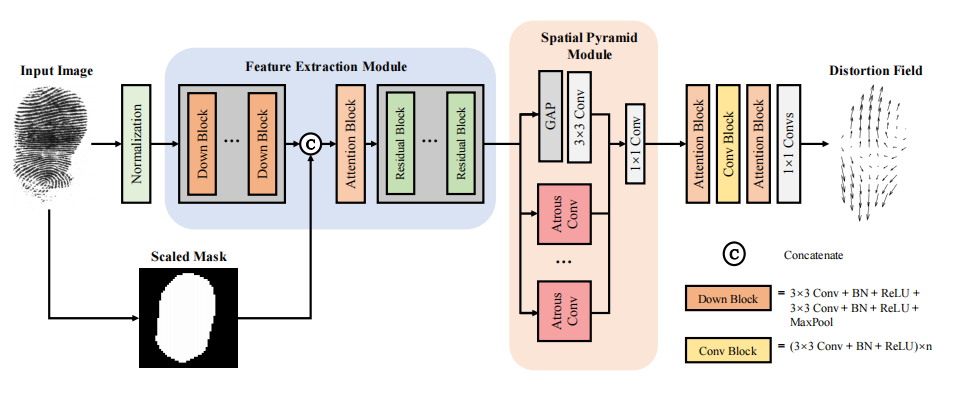
|
Xiongjun Guan , Yongjie Duan , Jianjiang Feng , Jie Zhou International Joint Conference on Biometrics (IJCB), 2022 Oral Presentation [Paper] [Code] [Slide] We proposed an end-to-end network to directly estimate a dense distortion field from a single fingerprint instead of its low dimensional representation. |
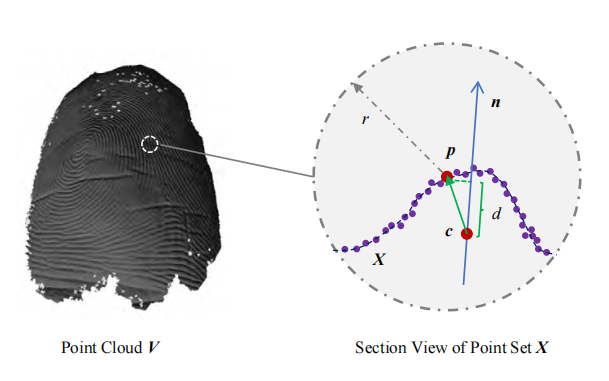
|
Xiongjun Guan , Jianjiang Feng , Jie Zhou Chinese Conference on Biometric Recognition (CCBR), 2021 Oral Presentation [Paper] [Slide] We proposed a visualization and pose-specific unfolding method for 3D fingerprints, which can improve the compatibility between 3D and 2D fingerprints in recognition. |
|
|
|
|